In the previous article in this series we stopped in the middle of building a set of classes that comprise a vendor-independent tool for maintaining database schemas. We had just introduced the concept of Metadata, and looked at how having an object representation of a set of database tables and columns can make it possible to modify and maintain them in an easy and flexible way.
JDBC is Sun's standard API for connecting to relational databases from Java.
JDBC is a single, common API that hides the peculiarities of each database
vendors specific API's from the Java programmer. It has been part of the JDK
since the 1.1 release of the JDK and is well documented in several excellent
books, especially JDBCTM Database Access from JavaTM: A
Tutorial and Annotated Reference, available from Addison-Wesley as part of
the Java Series authorized by Sunsoft. If you're not familiar with the basic
concepts of the JDBC, I recommend that you examine the documentation on the JDBC
that comes with the 1.1 JDK before you proceed with this article - the
documentation is well-written, and fairly short.
One of the parts of the JDBC that is *not* well covered in the existing literature - mostly because existing examples are more focused on the practical aspects how to retrieve and store data in SQL databases with JDBC - is the metadata component of JDBC. In fact, the JDK documentation for this portion of the JDBC is thin in any case, and downright misleading in some cases.
There are two interfaces that comprise the metadata portion of the JDBC. They
are DatabaseMetadata and ResultSetMetadata. DatabaseMetadata (according to the
class comment) "provides information about the database as a whole.". It
provides methods so that you can discover what a particular database &
driver combination can do. ResultSetMetadata is much more specific. It is "used
to find out about the types and properties of the columns in a ResultSet." In
short, it can examine what kind of information was returned by a database query
or a method of DatabaseMetadata.
In our particular problem we're interested in two aspects of using the JDBC
metadata facilities. They are:
To accomplish our first task we have to use a method in DatabaseMetadata,
getTables(). The getTables() method takes four parameters. They are:
The two "pattern" parameters take Strings that can match the JDBC pattern-matching format. A percent ("%") character will match 0 or more characters in a String, while an underscore ("_") character will match any single character. So, if you wanted to retrieve information on all tables containing the string "Employee",you could use "%Employee%" for the tableNamePattern parameter.
What this method returns is a ResultSet that has the following columns:
After we've obtained the information about the tables in the database we now need to examine the individual columns within those tables. That is the province of the getColumns() method. The getColumns() method has some peculiarities - it shows that despite the fact that Java has defined some standard interfaces, that not all database driver authors quite live up to those standards. The method comment describes a set of columns that should be returned in the ResultSet when this method is executed. What I have found is that the results of the method can differ from this set. Most database drivers are completely compliant to the standard - for instance, IBM's native DB2 drivers, and Oracles native drivers (both using SQLLIB and their 100% pure Java drivers) do return the stated set of columns. However, when you use the Intersolve's JDBC driver for Oracle with the JDBC-ODBC bridge, you get a different set. The moral is that you should still be careful about what drivers you use - always use the latest driver available.
These methods allows us to construct instances of our DbTable class directly from the metadata representations of the tables stored in the database schema. The question that then arises is how should the tables be created from this information? One possibility would be to allow the DbTables to read them in themselves - since it's difficult to read in an object that hasn't yet been instantiated, this could presumably be done through a static method in the DbTable class. But that isn't the best solution, since the process of creating a set of DbTables involves quite a lot of data manipulation, as we can see from the previous two methods.
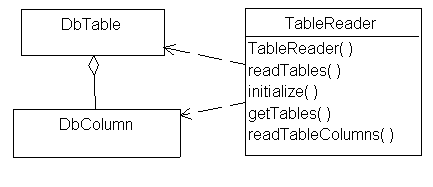
The best solution would be to create a new class whose purpose is to read tables. Let's call it (appropriately enough) TableReader. This is an application of a coding pattern that Kent Beck calls "Method Object". It basically converts a single, long, confusing method into a simple, easy-to-understand class.
The first method we want to examine in TableReader is readTables():
public void readTables() throws SQLException {
DatabaseMetaData metadata = null;
Connection currentConnection =
DbToolkit.getCurrent().getConnection();
metadata =
currentConnection.getMetaData();
String[] names = {"TABLE"};
ResultSet tableNames = metadata.getTables(null,"%", "%", names);
while (tableNames.next()) {
DbTable table = new
DbTable(tableNames.getString("TABLE_NAME"));
readTableColumns(metadata, table);
tables.addElement(table); }
}
The first thing we do in this method is obtain a database connection - this uses the DbToolkit class that we'll examine later - for now just assume that it's a valid open connection. Next we get the DatabaseMetadata using getMetadata() and then ask the metadata for the getTables() result set. We can then iterate over the set of results in the result set and create the DbTable instances that correspond to each of the table names in the result set. After instantiating each new instance, we then call the method readTableColumns() to get the column information, as is shown below:
public void readTableColumns(DatabaseMetaData meta, DbTable table)
throws SQLException {
ResultSet columns = meta.getColumns(null, "%",
table.getTableName(), "%");
while (columns.next()) {
String
columnName = columns.getString("COLUMN_NAME");
String datatype =
columns.getString("TYPE_NAME");
int datasize =
columns.getInt("COLUMN_SIZE");
int digits =
columns.getInt("DECIMAL_DIGITS");
int nullable =
columns.getInt("NULLABLE");
boolean isNull = (nullable == 1);
DbColumn newColumn = new DbColumn(columnName, datatype, datasize,
digits, isNull); table.addColumn(newColumn); }
}
This method basically reflects the previous method - it obtains the Column
information from the database metadata using the getColumns() method, and then
iterates through the columns creating an instance of DbColumn and filling it out
with the appropriate information. By the time these two methods complete we have
our tables Vector filled with instances of DbTable containing DbColumns matching
the metadata currently in the database. We can then begin modifying the metadata
and creating modification commands as we saw in the previous article, and later
replay the commands back on to the database.
There are two more pieces of "Magic" from the previous article that we need
to examine in order to understand how our design interacts with the classes in
the JDBC. One of the things that was explicitly left out of our previous
discussion was how the database commands actually get executed so that the
actual tables state changes to match that of our internal table
representation.
In the previous article we discussed a method called generateSQLWith() that
worked with the DbTable and the Command classes through to generate the
appropriate SQL statements to perform each command in a particular
platform-specific way. What we left out was the details of how that SQL is
executed. It turns out that solving that is in itself is another interesting
trip into the differences between database implementations.
The simplest and most straightforward way to execute these database commands
happens when any commands, be they ANSI SQL or vendor-specific stored procedures
or additional command syntax can be processed by the database drivers in the
same way. Both Oracle and SQL Server are alike in this respect, in that a user
with appropriate DBA privileges can execute any SQL command or vendor command.
The solution in this case looks like the following, which is the execute()
method in the OracleSqlGenerator classpublic void execute(String
sqlText) {
Connection current = null;
try {
current =
DbToolkit.getCurrent().getConnection ();
Statement stmt =
current.createStatement();
stmt.executeUpdate(sqlText);
} catch
(SQLException e) {
System.out.println("Unexpected Exception: " + e);
}
}
Here we simply use the standard features of the JDBC to create a Statement
from a Connection, and then execute an update command (JDBC considers any SQL
statement that is NOT expected to return a ResultSet (i.e. a SELECT statement)
to be an update). In this example we capture the SQLExceptions locally and
handle them by ignoring them. In a production system the commands would all need
to be executed together in a single transaction - we would then have to use
Connection.commit() at the end of all of the statements, or
Connection.rollback() if any of them failed.
The execute() method is called with each of the buildXXXSQL() methods in the SqlGenerator classes. This allows us to execute the entire stack of commands held by the TableBuilder at a single go, like the following shows:
public void executeStack(SQLGenerator gen) {
Enumeration
enum = commands.elements();
DbTable inProgress = originalTable.copy();
gen.beginStack();
while (enum.hasMoreElements()) {
AbstractCommand next = (AbstractCommand) enum.nextElement();
next.generateSQLWith(gen, inProgress);
next.applyTo(inProgress); }
gen.endStack();
}
The code is easy to understand. It simply iterates through the stack of
commands, instructing them first to generate (and execute) their SQL
equivalents, and then apply themselves to the table in progress. What is
slightly more interesting is the need to have the beginStack() and endStack()
statements surrounding the execution code. The reason for this gets into another
story about how flexible design helps deal with unexpected requirements.
Lately I decided to add another database to the list of databases supported
in the previous article. I had recently installed DB2 Universal in order to work
with some of IBM's e-business products and thought it would be helpful to be
able to administer my table schemas on DB2 in the same way as Oracle and SQL
Server. It seemed straightforward - I added a new SqlGenerator subclass called
DB2SqlGenerator that handled the SQL generation for the commands to add, rename
and delete columns, and I thought that I would be up and running in record time.
What stymied me was the implementation of the execute() statement in
DB2SqlGenerator.
DB2 comes with a set of utility programs (like Oracle and SQL Server) that
can dump data from a database onto a flat file, and recover it in the same way.
Since DB2 doesn't include specific ways to delete or rename columns (unlike
Oracle or SQL Server) I discovered I would have to implement the following
procedure to change a table
The problem is that the Export and Import commands cannot be executed from a
JDBC database driver like they can in the other databases. These commands can
only be executed through a special command-line interface that is provided with
DB2. So instead of using the previous solution of executing updates through
JDBC, I had to take another tack, first create a flat file containing the
commands executed during a session, and then invoke the DB2 Command line
interface tool. Unfortunately, there's a pretty significant overhead to invoking
the tool - on my 166 Mhz Pentium Windows NT machine, it takes a couple of
seconds for the command line prompt to come up before it executes any commands,
and another couple of seconds to shutdown after the commands are executed.
I therefore concluded that I would have to place all of the commands into a
single batch file for execution. After examining my design, I decided that I
just needed to open a file at the beginning of the executeStack() method and
close it at the end. But how could I do this without coding DB2-specific
dependencies into a class that should be generic to all databases? The
inspiration to my solution to that problem came from the pages of Design
Patterns in the form of two hook methods.
Design Patterns discusses the use of special "do-nothing" methods
called hooks in the context of the Template Method pattern. A Template Method is
a concrete method that is defined in an abstract superclass that relies on
behavior that has been deferred to the subclasses. A special type of method that
Template Methods may call is a "hook" method that does absolutely nothing in the
superclass. Subclasses may choose to override this behavior to do something at
some specific point in the processing of the template method.
A perfect instance of this is the start() and stop() methods of Applet.
Applet implements default versions of these methods that don't do anything.
Subclasses of Applet can override this behavior to do things like opening or
closing network or JDBC connections, beginning or ending animations, etc. You
don't necessarily have to be using the Template Method pattern to use the hook
idea, though. Any method can call hook methods, as long as it is understood that
the receiver of the method may be the class the hook is defined in, or any
subclass of that class.
This was the perfect solution to my problem. I implemented "Do-nothing" hooks called beginStack() and endStack() in my abstract SqlGenerator class and added the calls to those methods into executeStack(). My code worked for Oracle and SQL Server exactly as it had before. However, this allowed me to add an implementation of beginStack() in DB2SqlGenerator that opened the command file, and an implementation of endStack() that closed the command file and invoked the command line tool using that file as a parameter. I avoided a major rewrite of my classes, and avoided messy conditional code as well.
Having done everything so far described, I was left with two final problems
to complete my domain design. The unanswered questions were: How would I know
what kind of SQLGenerator subclass to instantiate when I needed to execute a
stack, and how do I know how to connect to the particular kind of database I
needed to execute the command against? The answers to these two questions came
together in a single class hierarchy.
Since I decided to solve the former before the latter, let's discuss them in
that order. Since the syntax of the Driver.connect() connection string differ
from database to database I decided to create a hierarchy of classes that would
be able to create connect to each database, and hold that database connection. I
created an abstract DbToolkit class and a subclass for each Database type. The
DbToolkit defined an abstract method called makeConnection() that hid the
details of the particular database connection from the rest of the system. Each
subclass defined it in its own specific way.
Once I had made that decision, I realized that, in effect, the DbToolkit was
acting like a kind of AbstractFactory (ala Design Patterns). It was a
short hop from that decision to then deciding to use the Factory Method pattern
to make the DbToolkit also responsible for creating instances of SqlGenerator
subclasses. I added another abstract method in DbToolkit called getGenerator()
that created and returned an instance of a SQLGenerator. In this way, I was able
to hide from the rest of the system what particular kind of SQLGenerator I was
using. The getGenerator() method was acting like a Factory Method in that simply
produced a product of a particular type - the subclasses decided what particular
class of product to instantiate. The following diagram shows the dependencies
that emerged from this design
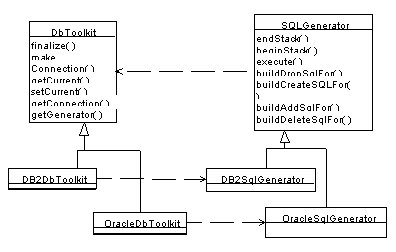
Each SQLGenerator depends on the DbToolkit to obtain the Connection that it
needs to execute its SQL, but other classes decide on what kind of SQLGenerator
to obtain by asking the Toolkit to create an instance. DbToolkit is itself an
instance of another pattern - the Singleton pattern. Since we can safely assume
that we will be working with only one database at a time in our design, we can
make DbToolkit contain a singleton instance of one of its subclasses in a class
variable. Of course, the changes to allow multiple databases to be available at
a single time would not be very complicated.
So, let's summarize these two articles by looking at the following table,
which shows the patterns we've used, and the classes in our design that
participated in those patterns.
| Pattern | Participants |
| Command | AbstractCommand and subclasses |
| Strategy | SqlGenerator and subclasses |
| Builder | TableBuilder |
| AbstractFactory, FactoryMethod, Singleton | DbToolkit |
The final tally shows that we used six design patterns (seven if you count the almost-use of Template Method). Not bad for a design that has less than twenty classes!